strauss-calibration-mental-model
In ecmult_multi, we model each algorithm's per-point cost as a linear function:
where is the per-point floor and is the fixed overhead amortized over the batch. We compute and by fitting a linear regression to benchmark data in the coordinate system.
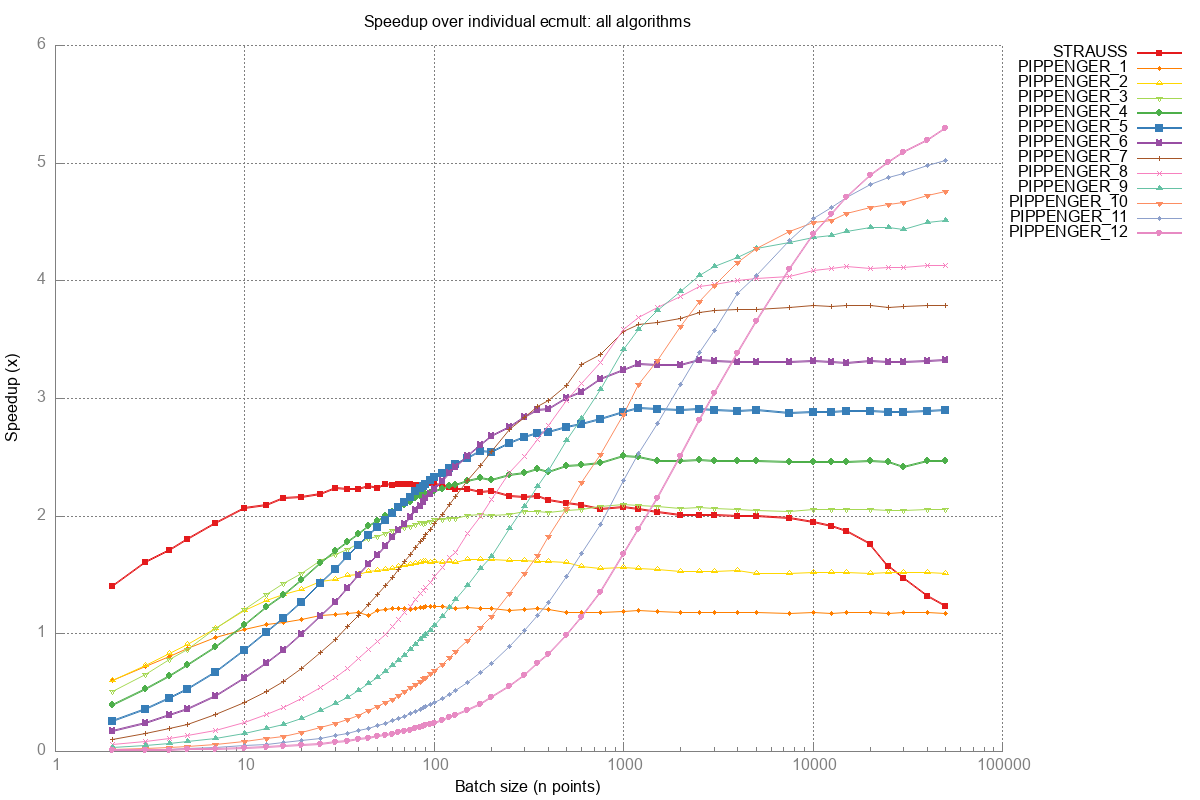
For Strauss, the calibration currently uses batches from , giving . But Strauss is only competitive up to about — after that, it flatlines and starts degrading. If we calibrate on just where Strauss is genuinely linear, we get .
So including the flatline region inflates C from 104 to 109. Why does including flat/degrading data push the intercept up?
The two coordinate systems
We measure Strauss performance in two different coordinate systems.
The speedup graph plots , where speedup . So the y-axis is proportional to .
The regression space plots , which is where the linear model lives. The y-axis here is just optime directly.
These two systems are related. Speedup is proportional to , so we're going from a system to an system. Both axes invert. This means we can translate the shape of the speedup graph into the regression space — as long as we remember to flip both axes.
Note: we're measuring optime per point, not total optime. Total optime grows with , so it wouldn't translate as cleanly. But per-point optime can flatline or decrease, and that's what makes this translation work.
Translating the Strauss curve
In the speedup graph, Strauss has two clear regions:
- Increases from to — the algorithm gets faster per point as it amortizes its fixed overhead.
- Flatlines from to — speedup stops improving. In reality it slightly decreases (Strauss degrades at large ), but it's close enough to flat for our reasoning.
Now translate to the regression space . The x-axis flips (, so left-right reverses) and the y-axis inverts (, so up-down reverses). The translated curve has:
- Flatline in — this is now the left portion of the plot.
- Increases in — this is the right portion, rising steeply.
The increasing part was measuring going up; flipping the y-axis means optime goes down in that region, so the rise becomes a decrease. And flipping the x-axis places it on the right. The flatline stays flat — roughly constant speedup means roughly constant optime.
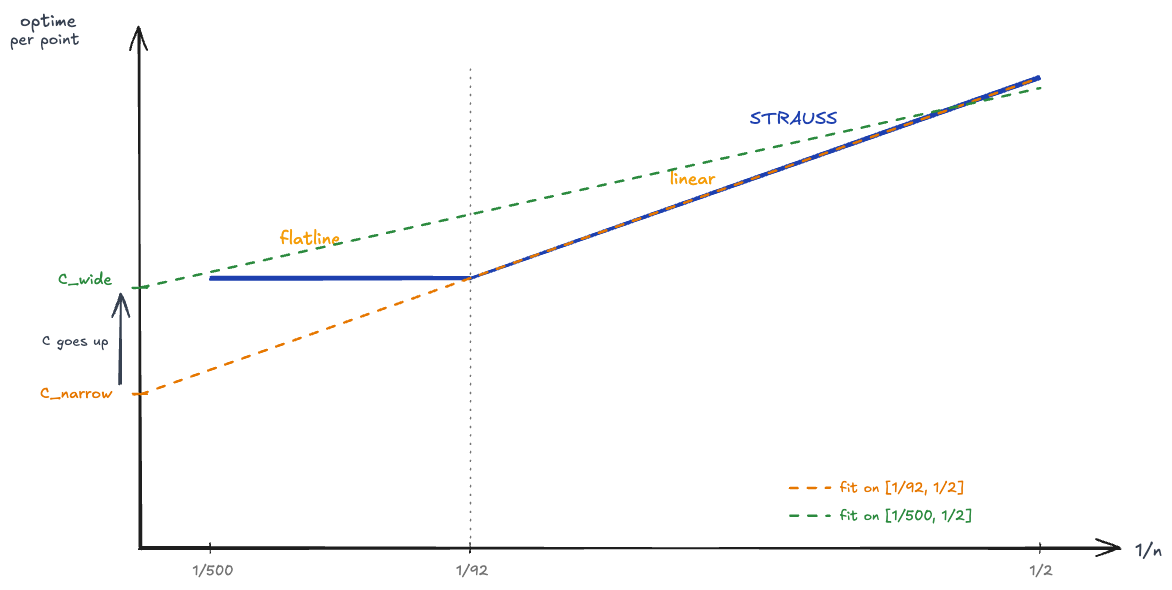
Why the flatline pushes C up
Here's the key geometric picture.
When we fit a line on just the rising portion , we get a steep line. Extrapolating this line leftward toward (the y-axis), the intercept ends up below the flatline level. This makes sense — the steep line is going down as it moves left, and it overshoots past where the data actually sits.
When we include the flatline points on the left side, the regression has to accommodate them. These points sit above the extrapolated line from the rising region. To fit them, the regression lifts its left end up (intercept increases) and becomes less steep (slope decreases).
In numbers:
- Narrow fit : us, scaled to
- Wide fit : us, scaled to
Including the flatline data pulls C up because the flatline sits above the linear extrapolation from the competitive region — Strauss never actually reaches the theoretical floor that the linear region predicts.
Why this inflation is useful
This C inflation turns out to be helpful. The algorithm selector picks the method minimizing using integer division. With (inflated), the Strauss-to-Pippenger w5 crossover falls at exactly in the C code — matching the empirical data almost perfectly. With (accurate linear fit), the crossover moves to , causing ecmult_multi to keep picking Strauss well past where Pippenger w5 is faster.
Better statistical fit, worse real-world algorithm selection. The "bad" linear fit is actually a feature.